
안녕하세요. 오늘은 파이썬의 웹 크롤링, 웹 스크래핑에 대해서 알아보도록 하겠습니다. 요즘 제가 관심 있게 공부하려는 부분입니다. 아직 파이썬도 공부하고 있는 단계라서 조만간 서점에 들러 책도 하나 사려고 합니다. 새 책을 보며 새로운 지식을 익힐 생각을 하니 벌써부터 신이 나네요. 그럼 웹 크롤링과 웹 스크래핑이란 과연 무엇인지 그 정의와 차이점 및 각각의 장단점에 대해서 알아보도록 하겠습니다.
| 웹 크롤링과 웹 스크래핑이란? |
웹 크롤링과 웹 스크래핑은 둘 다 웹사이트에서 데이터를 수집하는 기술이지만, 약간의 차이가 존재합니다.
우선, 웹 크롤링(Web Crawling)은 인터넷상의 웹 페이지를 주기적으로 탐색하여 정보를 추출하는 프로세스를 말합니다. 크롤러(Crawler)라고도 하는 프로그램을 사용하여 웹 사이트를 방문하고 해당 페이지의 모든 하이퍼링크를 따라가며 다른 페이지를 탐색합니다. 크롤러는 수집한 정보를 데이터베이스나 파일 시스템에 저장합니다. 그 이후에 데이터 마이닝, 머신 러닝 등 다양한 분야에서 활용할 수 있습니다.
반면, 웹 스크래핑(Web Scraping)은 웹 사이트에서 추출하는 기술로, 특정한 웹 사이트의 HTML 구조를 분석하고 원하는 데이터를 선택하여 추출하는 방식입니다. 웹 스크래핑은 특정한 데이터만 추출하는 것이 목적이기 때문에 크롤링보다 더 세부적이고 정교한 처리가 필요합니다.
두 개의 기술을 요약하자면, 웹 크롤링은 인터넷상의 모든 페이지를 방문하여 데이터를 수집하는 것이고 웹 스크래핑은 특정 웹 페이지에서 필요한 데이터만 추출하는 것입니다. 이 두 개의 기술은 둘 다 웹 데이터 수집에 중요한 역할을 하지만 목적에 따라 선택하여 사용해야 합니다.
| 웹 크롤링과 웹 스크래핑의 활용 |
웹 크롤링과 웹 스크래핑은 유사하면서도 약간의 차이가 있습니다. 따라서, 개발하려는 목적에 따라 웹 크롤링과 웹 스크래핑을 구분하여 사용하여야 합니다. 각각이 어떤 분야에서 활용되는지에 대해서 설명드리도록 하겠습니다.
웹 크롤링은 검색 엔진에서 사용되는 기술이며 인터넷상에 있는 대량의 데이터를 수집하는 데 주로 사용됩니다. 이를 통해 웹 검색, 쇼핑 검색, 뉴스 수집 등 다양한 분야에서 활용됩니다.
웹 스크래핑은 앞서 말씀드렸듯, 웹 페이지에서 필요한 데이터를 추출하는 기술이며 대부분의 경우 웹 크롤링과 함께 사용됩니다. 예를 들어, 인터넷 쇼핑몰에서 상품 정보를 추출하거나 뉴스 사이트에서 최신 기사를 수집하는 등 다양한 분야에서 활용됩니다. 또한, 소셜 미디어에서 사용자 정보를 추출하여 마케팅 분석에 활용하거나 의료 분야에서 환자 정보를 추출하여 분석하는 등 다양한 응용 분야에서 활용되고 있습니다.
| 웹 크롤링과 웹 스크래핑의 파이썬 라이브러리 |
파이썬에서는 웹 크롤링과 웹 스크래핑을 위한 다양한 라이브러리들을 제공합니다. 이 중 몇 가지 라이브러리들에 대해서 알아보도록 하겠습니다.
웹 크롤링 파이썬 라이브러리
- Requests : HTTP 요청을 송/수신하는 기능을 제공하는 라이브러리이며, 웹 페이지의 HTML 코드를 가져오기 위해 많이 사용됩니다.
- BeautifulSoup : HTML, XML 등의 마크업 언어로 작성된 문서를 파싱 하는데 사용되며 크롤링 한 데이터에서 원하는 정보를 추출하는데 많이 활용됩니다.
- Scrapy : 웹 크롤링 및 웹 스크래핑을 위한 프레임워크이며 크롤링 한 데이터를 저장하고 가공할 수 있는 기능을 제공합니다.
웹 스크래핑 파이썬 라이브러리
- BeauifulSoup : 웹 크롤링은 물론, 웹 스크래핑에서도 가장 많이 사용되는 라이브러리 중 하나입니다. 저 또한, 웹 스크래핑을 학습하면서 사용했던 라이브러리입니다.
- LXML : 파이썬에서 사용할 수 있는 XML 파서 라이브러리이며 HTML을 처리하는데 많이 활용됩니다.
- Scrapy : 웹 크롤링은 물론, 웹 스크래핑도 지원하는 프레임워크이며 XPath를 이용한 데이터 추출 기능을 제공합니다.
이 외에도 Selenium, Pandas, NumPy 등의 라이브러리가 있습니다.
| 크롬 개발자 도구를 이용한 웹 스크래핑 |
마지막으로, 크롬의 개발자 도구를 이용하여 웹 스크래핑하는 방법에 대해서 알아보도록 하겠습니다. 크롬의 개발자 도구를 사용하면 웹 페이지의 HTML, CSS, JavaScript 등을 검사하고 수정할 수 있습니다. 따라서, 이를 활용하여 웹 페이지에서 필요한 데이터를 스크래핑할 수 있습니다. 아래는 크롬 개발자 도구를 이용한 웹 스크래핑의 예시입니다.
- 크롬에서 스크래핑할 웹 페이지를 열어 줍니다.
- 키보드에서 F12 키를 눌러 개발자 도구를 열어줍니다. (Ctrl + Shift + I 키를 눌러 개발자 도구를 열 수 있습니다.)
- 개발자 도구의 Elements 탭에서 원하는 데이터가 있는 HTML 요소를 찾습니다.
- 해당 요소의 선택자(CSS Seletor, XPath 등)를 복사합니다.
- 파이썬에서 BeautifulSoup, LXML 등의 라이브러리를 사용하여 데이터를 추출합니다.

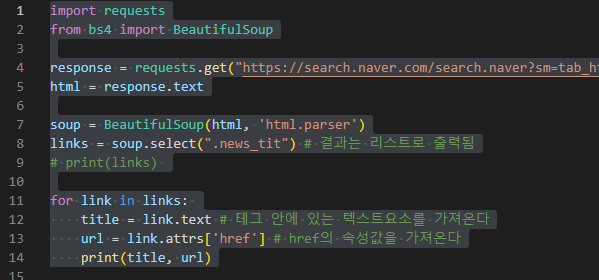
오늘은 여기까지 웹 크롤링과 웹 스크래핑에 대해서 알아보았습니다. 다음엔 직접 코딩하여 글을 작성해 보도록 하겠습니다.
'Programming Language > Python' 카테고리의 다른 글
| [Do it! 점프 투 파이썬 4, 5일차] 파이썬 프로그래밍의 기초, 자료형(딕셔너리 자료형, 집합 자료형, 불 자료형, 변수) (3) | 2024.03.28 |
|---|---|
| [Do it! 점프 투 파이썬 3일차] 2장_파이썬 프로그래밍의 기초, 자료형 (리스트 자료형, 튜플 자료형) (9) | 2024.03.27 |
| [Do it! 점프 투 파이썬 2일차] 2장_파이썬 프로그래밍의 기초, 자료형(숫자형, 문자열 자료형) (3) | 2024.03.26 |
| [Do it! 점프 투 파이썬 1일차] 1장_python이란 무엇인가? (3) | 2024.03.24 |
| python 공부 시작! (3) | 2024.03.24 |




댓글